|
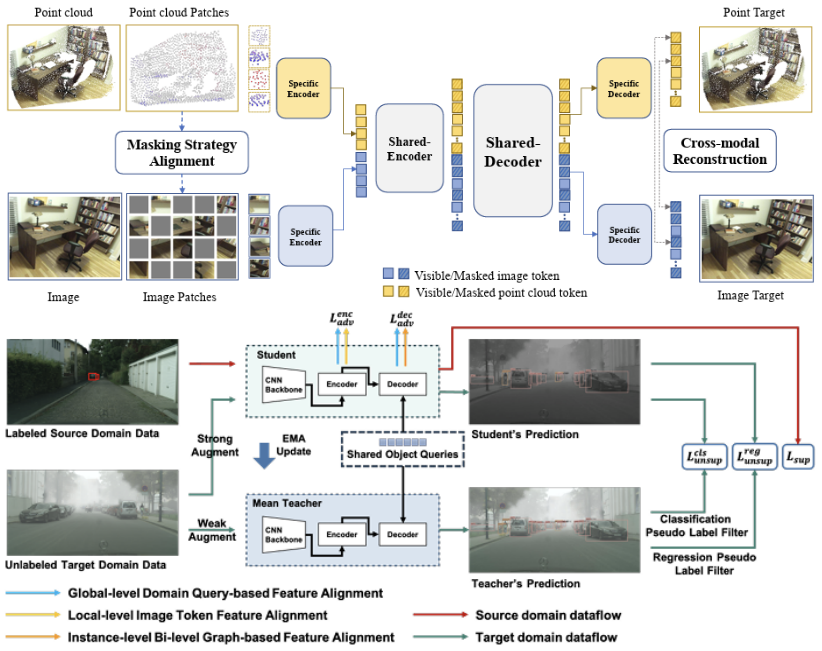
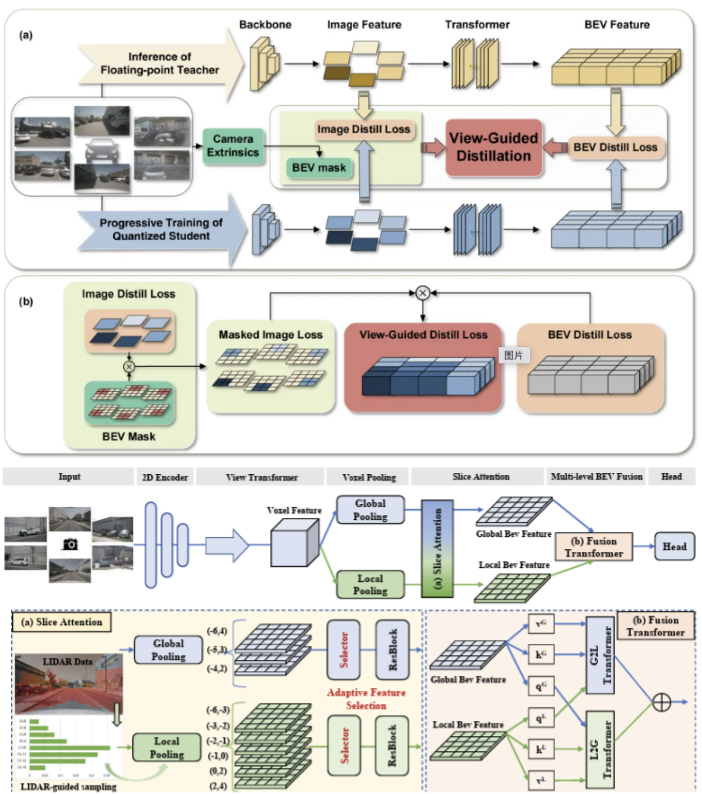
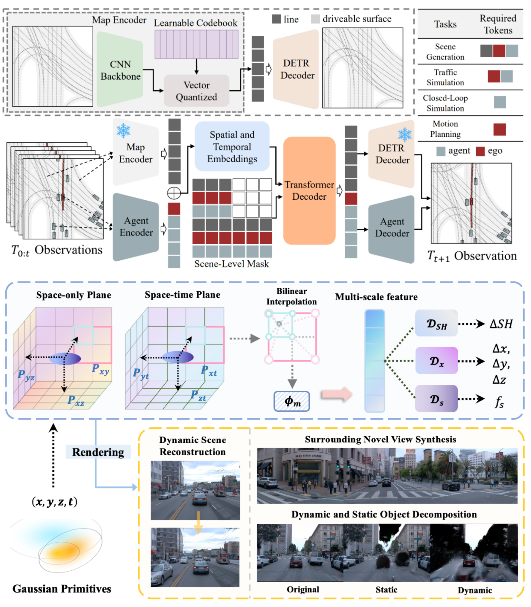
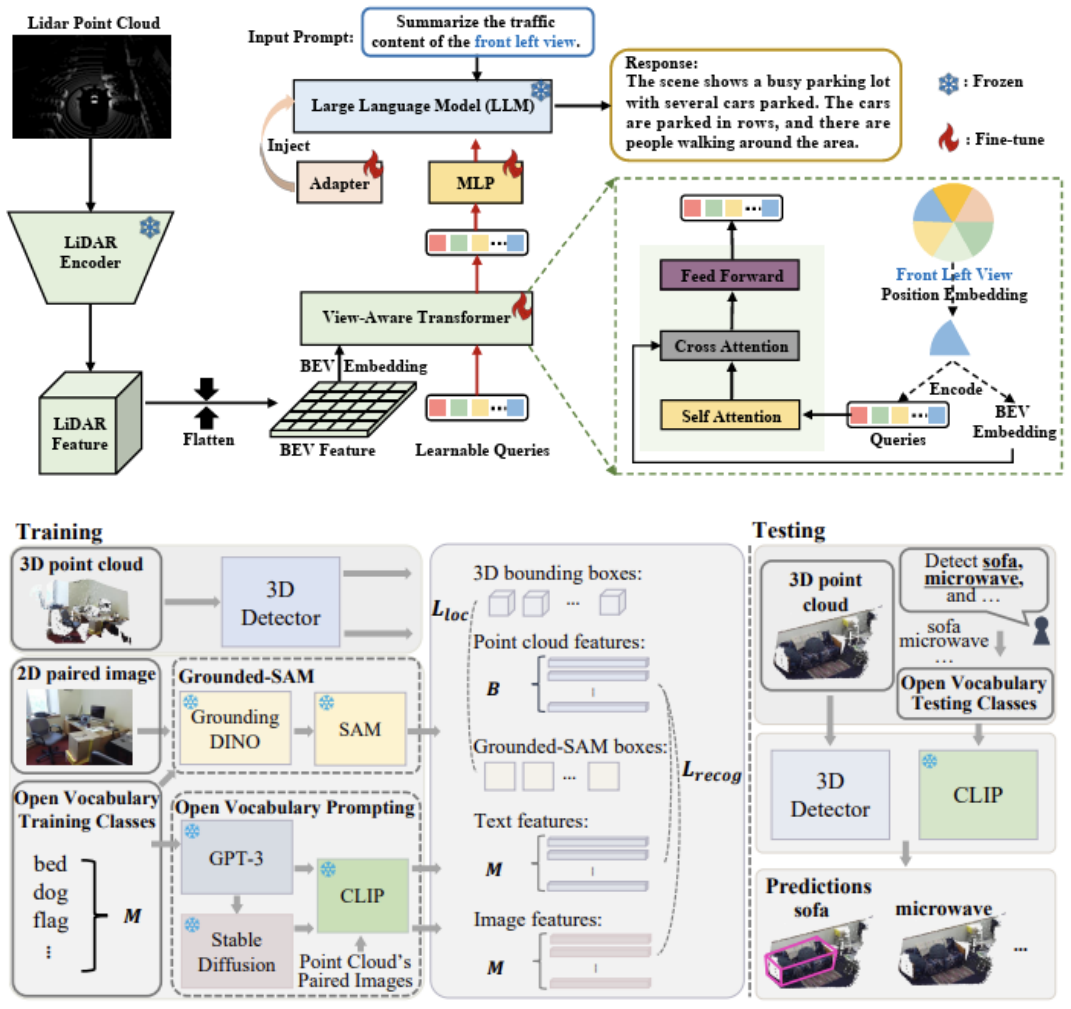
(1) 在自动驾驶2D感知领域,在提高感知准确率方面,提出采用掩蔽自动编码器PiMAE (CVPR'23),利用其自监督学习能力对点云和RGB图像数据的交互进行深入探索,以增强模型对物体识别和图像恢复的准确率。在增强感知模型泛化性方面,提出MoFME混合专家结构 (AAAI'24),通过专家间的权重共享,可以以低开销扩大专家数量,并行去除多种不利天气效应,增强了模型在下游分割和分类任务中的泛化能力,实验证明MoFME在图像恢复质量上比基线性能高出0.1-0.2 dB,并且在节省了超过72%的参数和39%的推理时间的同时,达到了与最先进性能兼容的表现。提出TupleInfoNCE (ICCV'21),通过对比学习策略实现了多模态数据之间的有效融合,以及MTTrans (ECCV'22),通过领域查询基于特征对齐、双级图基原型对齐以及基于Token的图像特征对齐在局部、全局和实例级别对图像和对象特征进行对齐,增强了模型在面对不同任务和环境时的泛化能力。为进一步提升二维图像处理的效率,通过深度概率方法和对比损失进行表示学习 (IEEE TCD'22),优化算法生成高效的正负样本,显著降低了对大规模标注数据的依赖,提高了模型的处理速度和实时性。在视频数据的识别处理方面,提出了一种融合目标注意力掩蔽生成网络视频分割模型 (ICIP’20),结合了空间和时间信息,利用多支路网络学习对象的外观、位置和运动特征,并引入目标注意力模块进一步挖掘上下文信息,在多个视频语义分割数据集上表现出优越的分割准确率。提出了一种半监督视频目标分割方法 (ISCAS’20),利用混合编解码器网络结合光流信息生成像素级前景目标分割,并通过两阶段的方式交替训练,在视频目标分割任务上取得了领先的性能。在鸟瞰视图应用于自动驾驶方面,团队发现典型实际跨域场景中存在的显著领域差异,并全面解决了多视角3D物体检测的领域适应(DA)问题,提出了一个多空间对齐师生(MATS)框架来缓解领域偏移累积问题,在三个跨域场景上进行了BEV 3D物体检测实验,在性能上超越了目前业内最新水平。上述研究在全自主无人机电力巡检场景中部署应用 (ICRA’21),将二维感知方法部署在边缘端,无人机能够实时检测视野中兴趣目标的位置,并自动调节相机对准目标,拍摄清晰的巡检照片。申请团队提出了一系列的算法进行高效泛化地物体识别与追踪 (IJCV’21, TMM’21, IJCV’21, AAAI’20)。 |
|